DAT202.1x Processing Big Data with Hadoop in Azure HDInsight: Course highlights
End of May I obtained my “DAT202.1x – Processing Big Data with Hadoop in Azure HDInsight” certificate from Microsoft by following the course at edx,org. Since there has been lots of new information for me to digest, I have gone through the course once more trying to summarize the most important parts of it. This post is the result of my attempt to create a concise summary of the course. If you need more in-depth information feel free to search for it on the internet; you are sure to find what you will be looking for 🙂.
Preparatory steps
In order to be able to follow along during the course, you will need to create a free account for Microsoft Azure and also download a few helpful tools. This is all explained at the preparatory steps that precede the first module of the course titled “Getting started with HDInsight”
1. Getting started with HDInsight
During this module you will learn what Big Data, MapReduce, Hadoop and HDInsight is and you will get familiarized with setting up an HDInsight cluster in Azure. You will also get to run MapReduce jobs and use Powershell and the client tools in order to interact with the cluster you have created.
The first thing that stroke me was the wealth of the resources you can choose from at the Azure portal.
Secondly, I liked the user interface a lot, with the different slates opening to the right
Although creating a new resource is quite easy, the different options you are presented with are somewhat overwhelming. And you should also not forget to delete the cluster you have created if you don’t what to use it anymore, otherwise your credit card will be charged even though your cluster might not de processing any data. Thankfully you do get some free credits with your account in order to start experimenting.
HDInsight is, simply put, open-source Hadoop running on Azure, more specifically, a Hortonworks (and after the merger a Cloudera) implementation of Hadoop running on virtual machines. In HDInsight though, HDFS is implemented differently. The storage is not managed by the actual hard disks connected to the virtual machines, but it is moved into the cloud, into either the Azure storage blob or into the Azure data lake. Beacuse of that, if you don’t need the cluster, you can take it down and still keep the data.
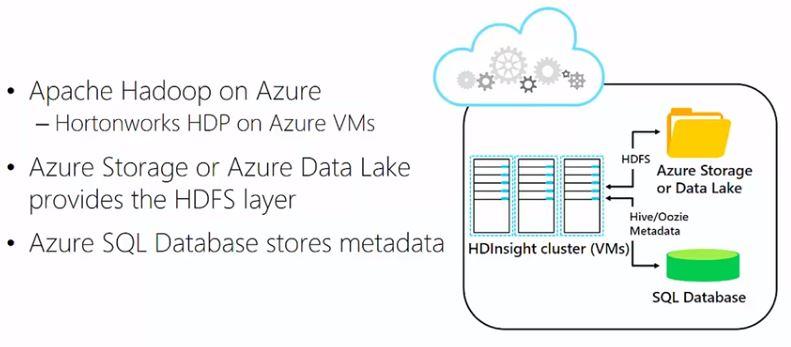
2. Processing Big Data with Hive
Hive projects a schema on text files making them behave like database tables, which means that you can execute SQL-like queries against those files. Hive organises the underlying data in folders that reside on HDFS and contain text files.

Although Hive executes MapReduce jobs, it does not necessarily use the MapReduce engine. Nowadays, making use of the Tez engine results in beter performance as Tez omits unnecessary Map jobs. This is something you don’t have to worry about though, as it is all getting taken care of by Azure.
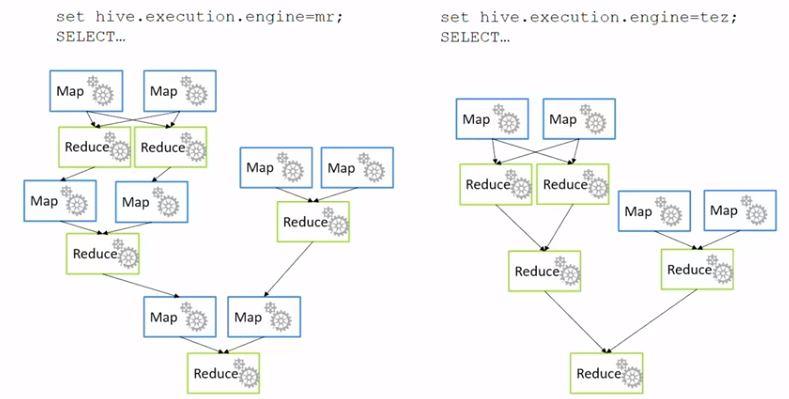
By executing consecutive Hive queries against those files, you can perform batch operations in order to clean, transform and process the data, getting them to a usable format and possibly storing them in a database or creating a report with, for instance, PowerBI or even Excel.
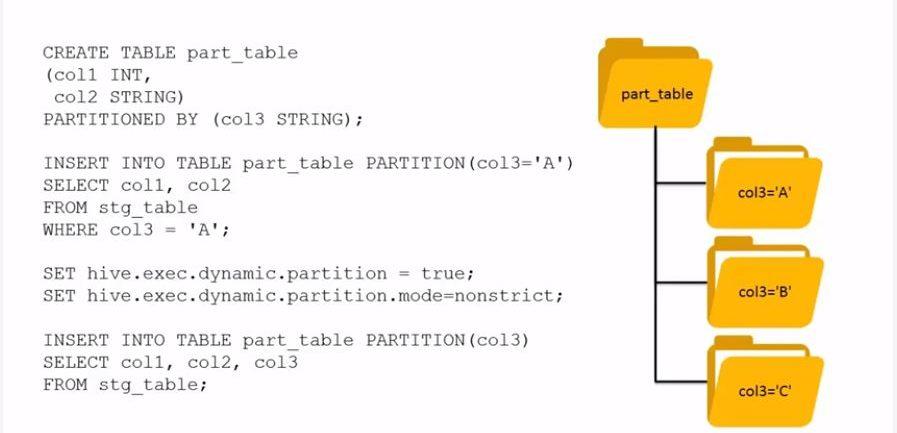
Since Hive is a technology by which large amounts of data can be processed, performance optimization is of paramount importance. Partitioning, skewing and clustering are three techniques that can be used to optimize the performance.
- Partitioning will create folders named exactly as the partition, that will contain files that satisfy the partitioning condition
- Skewing will either create folders or files depending on whether the optional STORED AS DIRECTORIES is used
- Clustering will create the specified buckets as files, based on a hashing algorithm


3. Going beyond Hive with Pig and Python
Executing consecutive queries with Hive is fine, but Pig and the respective scripting language Pig Latin might be preferable if you need to perform a series of data operations.
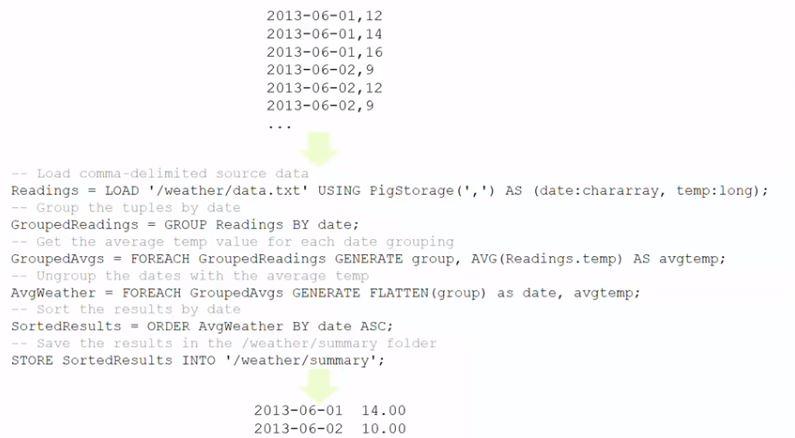
Pig operates on relations. You will have to write Pig Latin statements that will create these relations from the source data and then you can create the second relation from the first relation, the third relation from the second relation and so forth, each time transforming the data until you get them into the structure and shape that you wanted them to be.

Just as with Hive, the relations are loaded using a schema that is projecting a table structure at runtime. Again, similarly to Hive, data that do not fit to the defined schema will be replaced by NULLs. There are lots of different Pig operations that can be applied to the data, however the Tez or MapReduce engine will be called only by calling either the DUMP or STORE operation.
If you need to perform custom data processing, then you can use Python in order to write User Defined Functions (UDFs) since Python is a simple and straighforward scripting language that is natively supported in Azure. You could also alternatively use Java or any other language like, for instance, C#. You could also use Java or .Net to write your own MapReduce jobs, which will be more complicated.
Hive uses UDF’s by Hive streaming, while Pig uses UDFs by employing Jython, which is a Java implementation of Python.
4. Building a Big Data workflow
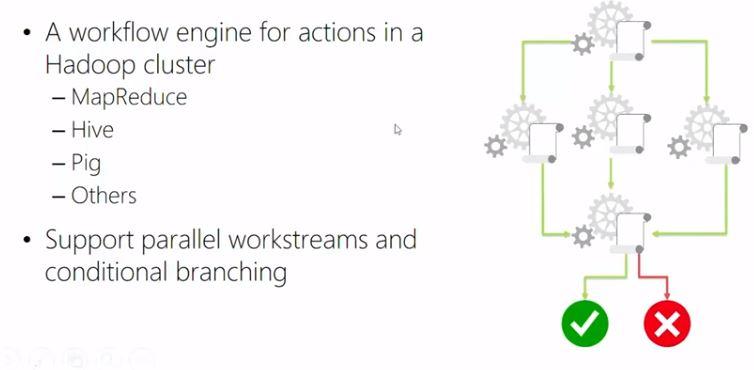
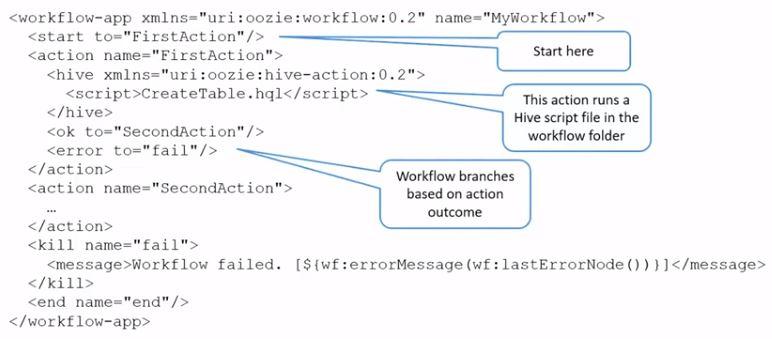
In typical Big Data processing scenarios you will need to combine different technologies, for example you might need to run a Pig job and then a Hive job or you might need to run a MapReduce job or lots of different processing steps in order to get that data into the structure that you need. This can be achieved by using Oozie. Oozie uses an XML workflow file that defines the actions and process and together with that there will be some scripts running the actions. You could write your own application in your prefered programming language that will call Oozie or Hive or Pig jobs in order to perfrom the necessary tasks. If you need to transfer data to and from relational databases, you can use a technology named Sqoop.
In addition to the theory, there will be lots of lab exercises for you to practice and assessment to test your knowledge and earn your certification.